🔐 Incident Response, Business Continuity and Disaster Recovery
This article is part 2 (of 6) of a series to help you prepare for the ISC2 Certified in Cybersecurity (CC) certification.
The CC certification is a foundational certification that covers the core concepts and principles of cybersecurity. It is designed for anyone who wants to enter or progress in the cybersecurity field, regardless of their background or experience.
🎓 Become Certified in CyberSecurity series: https://www.jbbres.com/files/cc-2023.html
🎓 ISC2 Certified in Cybersecurity (CC): https://www.isc2.org/Certifications/CC
Maintaining availability for business operations in the face of unexpected disruptions is a primordial concern for any organisation. Through this article, we will discuss the three distinct plans that organisations usually have in place to ensure business continuity: Incident Response (IR), Business Continuity (BC), and Disaster Recovery (DR).
The Incident Response plan is designed to respond to abnormal operating conditions and keep the business operating. An Incident Response team comprising cross-functional individuals from management, technical, and functional areas of responsibility is responsible for assessing the damage caused by an incident, implementing recovery procedures, and ensuring future measures to prevent recurrence.
The Business Continuity plan is designed to keep the organisation operating through the crisis. It includes details on when to enact the plan, notification systems, and contact numbers for critical third-party partners, external emergency providers, vendors, and customers. It provides the team with immediate response procedures and checklists and guidance for management.
Finally, if both the Incident Response and Business Continuity plans fail, the Disaster Recovery plan is activated to return operations to normal as quickly as possible. The Disaster Recovery plan may include department-specific plans, technical guides for IT personnel responsible for implementing and maintaining critical backup systems, full copies of the plan for critical disaster recovery team members, and checklists for certain individuals.
The article aims to help understand how organisations respond to, recover from, and continue to operate during unplanned disruptions.
Incident Response
Incident Response (IR) is a set of procedures designed to detect, analyse, contain, eradicate, and recover from security incidents that may threaten an organisation's information assets. IR plans are vital for organisations as they help minimise the impact of a security incident and reduce the time to return to normal business operations.In the context of incident response, it is important to have a clear understanding of the terminology used to describe different types of security incidents and potential threats. Here are some commonly used terms:
- Threat: A threat is any event or occurrence that could potentially cause harm to an organisation's information assets. Threats can come from both internal and external sources, and can include cyber attacks, natural disasters, and human error. Incident response teams should be aware of potential threats and have plans in place to mitigate them.
- Vulnerability: A vulnerability is a weakness in a system or application that can be exploited by attackers to gain unauthorised access. Vulnerabilities can be caused by software bugs, misconfigured settings, or poor security practices. It is important for organisations to regularly assess their systems and applications for vulnerabilities and apply patches or other security measures as needed.
- Zero Day: A zero-day vulnerability is a security vulnerability in a system or application that is unknown to the vendor and has not been patched. Zero-day exploits can be particularly dangerous because there may be no known way to mitigate the vulnerability. Attackers may keep zero-day exploits secret and use them to carry out targeted attacks against specific organisations or individuals.
- Exploit: An exploit is a technique used by attackers to take advantage of a vulnerability in a system or application to gain unauthorised access. Exploits can come in many forms, such as code injection, buffer overflow, or SQL injection. Attackers may use known exploits that have not been patched, or zero-day exploits that have not yet been discovered by vendors.
- Event: An event is any occurrence that could potentially lead to a security incident. This could include an unexpected network outage, suspicious activity on a server, or an employee reporting a lost or stolen device. Not all events will result in a security incident, but they should be monitored and investigated to determine if action is needed.
- Incident: An incident is a security event that compromises the confidentiality, integrity, or availability of an organisation's information assets. Examples of security incidents include data breaches, denial-of-service attacks, and malware infections. Incident response teams are responsible for detecting and responding to security incidents in a timely manner.
- Intrusion: An intrusion is when an attacker gains unauthorised access to an organisation's systems or network. This could be through exploiting a vulnerability, using stolen credentials, or other means of gaining access. Once an attacker has gained access, they may attempt to escalate privileges, exfiltrate data, or install malware.
- Breach: A security breach occurs when an attacker gains unauthorised access to sensitive information. This could include personally identifiable information (PII), financial data, or confidential business information. A breach could be the result of a targeted attack, malware, or human error such as misconfigured settings or weak passwords.
The incident Response Plan
To effectively handle security incidents that may affect the organisation, it is essential to establish a structured approach and document it in an Incident Response plan. The objective of an Incident Response plan is to create a framework for responding to security incidents that limits harm and interruptions to the organisation, and guarantees operational continuity.The plan typically includes procedures for identifying and analysing security incidents, responding to incidents, and recovering from them. It also identifies key personnel who will be responsible for executing the plan, as well as communication protocols, escalation procedures, and guidelines for engaging external parties, such as law enforcement or regulatory bodies.
The Incident Response plan is a living document that requires regular maintenance and testing to ensure that it remains effective and up-to-date with the organisation's evolving security needs and threats.
An Incident Response plan typically consists of four main components, which are interconnected and build upon each other.
- The first component of incident response is preparation, which involves developing a plan and identifying key personnel who will be responsible for executing it. The plan should define roles and responsibilities, provide clear instructions on what to do in the event of an incident, and outline procedures for communication, escalation, and recovery. This phase also includes training and regular exercises to ensure that the team is prepared to respond effectively to incidents.
- The second component is detection and analysis, which involves identifying and confirming that an incident has occurred, assessing the scope and impact of the incident, and determining the appropriate response. This phase may involve gathering information from various sources, such as security tools, network logs, and user reports. The goal is to quickly identify the nature of the incident and its potential impact on the organisation.
- The third component is containment, eradication, and recovery, which involves taking immediate actions to contain the incident, eliminate the threat, and restore normal operations as quickly as possible. This may include isolating affected systems or networks, removing malicious code, and restoring data from backups. The focus is on minimising the impact of the incident and preventing it from spreading further.
- The final component is post-incident activity, which involves documenting the incident, conducting a post-mortem analysis to identify lessons learned, and updating the incident response plan accordingly. This phase also includes communicating with stakeholders and other relevant parties, such as law enforcement or regulatory bodies, as necessary.

For example, imagine that a company's security team receives an alert that a critical server has been compromised. The first step is to activate the incident response plan, which outlines the roles and responsibilities of the team members. The team works together to confirm that an incident has occurred and assess the scope and impact of the incident. Once the team has identified the nature of the incident, they take immediate action to contain the incident by isolating the affected server and any associated systems. They then work to eradicate the threat and restore normal operations as quickly as possible. After the incident has been resolved, the team conducts a post-mortem analysis to identify any gaps in the incident response plan and updates it accordingly.
The Incident Response Team
The Incident Response Team (IRT) is a group of individuals responsible for responding to and managing a security incident within an organisation. The IRT is typically a cross-functional group of individuals who represent the management, technical, and functional areas of responsibility most directly impacted by a security incident.The primary role of the IRT is to identify, contain, eradicate, and recover from security incidents as quickly and effectively as possible. The IRT is responsible for determining the amount and scope of damage, whether any confidential information was compromised, and implementing recovery procedures to restore security and recover from incident-related damage.
There are three possible models for an IRT:
- Leveraged IRT: This model is composed of individuals from various departments who are temporarily assigned to the team when an incident occurs. These individuals have primary job responsibilities within their respective departments but are trained on incident response and the organisation's incident response plan. When an incident occurs, they are called upon to contribute their expertise and experience to the IRT.
- Dedicated IRT: This model is composed of individuals who are solely responsible for incident response and are available 24/7. These individuals have specialised skills and training in incident response and are solely dedicated to responding to security incidents. They are typically responsible for managing the organisation's incident response plan and coordinating with other members of the IRT to respond to security incidents.
- Hybrid IRT: This model is a combination of both models, with some members of the team dedicated to incident response and others leveraged as needed. This model allows the organisation to have a core group of individuals with specialised skills and training in incident response, while also leveraging the expertise of individuals from other departments as needed.
Business Continuity
Business continuity (BC) is the process of creating and implementing plans and procedures to ensure that people remain safe and that the organisation can continue to operate or quickly resume operations after a disruptive event.To ensure business continuity, companies typically create a BC plan. Such plan typically includes procedures for responding to both natural and man-made disasters, such as earthquakes, floods, fires, cyber-attacks, and pandemics. The goal of business continuity planning is to minimise downtime and ensure that critical business functions can continue in the event of an interruption.
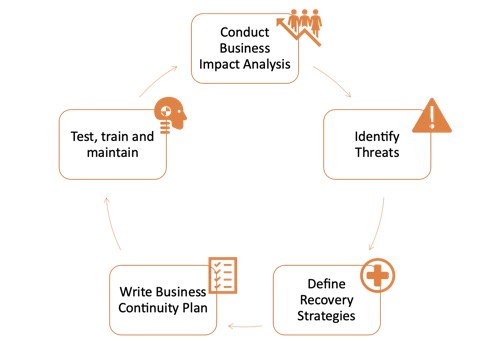
To create the BC plan, organisations first seek to understand the impact that a disruption would have on their activities through a Business Impact Analysis, and assess the key threats that would apply to them. They then can define adequate recovery strategies and document them in a formal plan.
Business continuity planning is important for several reasons. First, it helps to ensure the survival of an organisation by reducing the impact of disruptions and minimising downtime. Second, it helps to maintain customer confidence and loyalty by ensuring that critical services and products are available even in the event of a disruption. Third, it can help to protect an organisation's reputation by demonstrating to customers, employees, and stakeholders that the organisation is prepared for emergencies.
Business Impact Analysis
A business impact analysis (BIA) is the first key component of business continuity planning. It is the process of identifying and evaluating the potential impacts of disruptions on an organisation's critical business functions, processes, and systems. A BIA helps to determine the criticality of each business function and the resources required to resume operations in the event of a disruption. It also helps to prioritise recovery efforts and allocate resources based on the potential impact of disruptions. A BIA typically involves the following steps:- Identifying critical business functions and processes
- Identifying the resources required to support each business function or process
- Determining the potential impact of disruptions on each business function or process, such as financial impact, operational impact, or regulatory impact
- Prioritising business functions or processes based on their criticality and the potential impact of disruptions
Threat Assessment
Threat assessment is the process of identifying and evaluating potential threats to an organisation's operations, assets, and stakeholders. The goal is to understand the likelihood and potential impact of different types of risks, such as natural disasters, cyber-attacks, and supply chain disruptions. The risk assessment process involves identifying and analysing different types of risks, assessing the likelihood and potential impact of each risk, and prioritising them based on their severity. The output of the risk assessment process is a list of risks ranked in order of priority, along with recommendations for risk mitigation and management strategies.Recovery Strategies
Once an organisation has identified and prioritised potential risks, the next step is to develop recovery strategies for each identified risk. Recovery strategies are actions and procedures that an organisation can take to minimise the impact of an event and recover from it as quickly as possible. Recovery strategies may include:- Backup and recovery procedures: A critical part of disaster recovery planning is the regular backing up of important data and systems to ensure they can be restored in case of a disaster. Backup and recovery procedures should be tested regularly to ensure they are working effectively.
- The 3-2-1 backup rule is a widely recommended strategy for ensuring robust data backup and recovery. This rule advocates having three copies of your data stored across two different types of media, with one of these copies stored off-site. Implementing this rule as part of backup and recovery procedures significantly enhances data resilience. For example, an organisation can keep the original data on an office server, a second copy on an external hard drive kept in a safe, and a third copy stored off-site in a secure cloud storage service.
- Alternate work locations: In the event of a disaster, it may be necessary for employees to work from alternate locations, such as a secondary office or a remote work setup. Organisations should have plans in place for these scenarios, including procedures for accessing necessary systems and equipment.
- System high availability: High availability systems are designed to minimise downtime by providing redundant resources that can take over in case of a failure. This can include redundant servers, storage, and network devices. The goal is to provide continuous availability of critical systems and services.
- Fault tolerance: Fault tolerance is the ability of a system to continue operating in the event of a hardware or software failure. This is achieved through redundant resources and automatic failover mechanisms. For example, a server cluster might have multiple nodes, and if one node fails, the others can continue to operate without interruption.
- Crisis communication plans: In the event of a disaster, clear communication is critical to ensuring the safety of employees, informing stakeholders, and minimising damage. Crisis communication plans should include procedures for notifying employees, customers, vendors, and other stakeholders, as well as a designated spokesperson and messaging templates for different scenarios.
Business Continuity Plan
The Business Continuity Plan (BCP) is the central document that outlines an organisation's response to a disruption. It is a set of policies, procedures, and protocols that an organisation follows to ensure the continuity of critical business functions in the event of a disruption.The BCP should include:
- Under which condition the plan should be enacted.
- A detailed list of the response team members, including multiple contacts methods and alternative members.
- Roles and responsibilities for each member of the response team.
- A detailed list of critical business processes and systems, along with recovery strategies and detailed procedures and checklist for each.
- The notification processes and systems (such as a call tree) to alert employees that the BCP has been enacted.
The BCP should be regularly reviewed and updated to reflect changes in the organisation's operations, risks, and recovery strategies.
One key aspect of a BCP is the establishment of Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs). The RTO is the maximum acceptable downtime for critical business operations after a disruption, and the RPO is the maximum amount of data loss that the organisation can tolerate. These objectives help to guide the development of recovery strategies and ensure that the organisation's recovery efforts are aligned with its business priorities.
Testing, Training, and Maintenance
Once a business continuity plan has been developed, it is important to regularly test and update the plan.Testing can help to identify any gaps in the plan, as well as areas that may need improvement. It is recommended that businesses conduct regular testing exercises to ensure that the plan is effective and up-to-date. This may involve tabletop exercises, simulations, or full-scale drills.
Training is also an important component of business continuity planning. Employees should be trained on the procedures and processes outlined in the plan, as well as their individual roles and responsibilities. This can help to ensure that everyone knows what to do in the event of an emergency, and can help to minimise confusion and errors.
Maintenance is also critical to ensuring that a business continuity plan remains effective. The plan should be regularly reviewed and updated to reflect changes in the business environment, such as changes in personnel, technology, or facilities. This can help to ensure that the plan remains relevant and effective over time.
Crisis Management
Crisis management is the process of managing a crisis situation in a way that minimises damage and disruption to the organisation. This may involve coordinating emergency response efforts, communicating with stakeholders, and implementing contingency plans. Crisis management is typically focused on the immediate response to an incident, and is often handled by a separate team from the business continuity team.In crisis management, communication is critical. Effective communication can help to ensure that everyone is on the same page, and can help to minimise confusion and errors. It is important to have clear communication protocols in place, as well as trained personnel who are able to communicate effectively in a crisis situation.
Disaster Recovery (DR) and Restoration
The final stage of the incident response and business continuity process is recovery and restoration. This stage involves returning to normal business operations after a disruption or disaster. The objective of the recovery and restoration stage is to minimise the impact of the disruption and return the organisation to normal operations as quickly as possible.The recovery and restoration stage involves several key activities, including:
- Recovery of critical business functions: This involves restoring the organisation's critical business functions and processes to their normal state. This may involve restoring IT systems, data, and applications, as well as essential business processes and functions.
- Restoration of non-critical business functions: Once the critical business functions have been restored, non-critical business functions can be restored. This may include restoring office facilities, equipment, and other non-essential systems and processes.
- Verification of recovery: Once the critical and non-critical business functions have been restored, it is important to verify that they are working as expected. This involves testing the systems and processes to ensure that they are fully functional and can support the organisation's business operations.
- Continuous improvement: The final step in the recovery and restoration stage is to evaluate the effectiveness of the recovery and restoration process and identify areas for improvement. This may involve conducting a post-mortem analysis to identify lessons learned and updating the business continuity plan to reflect these lessons.
Overall, the recovery and restoration stage is critical to the success of the business continuity process. It ensures that the organisation can quickly recover from a disruption or disaster and resume normal business operations. This can help to minimise the financial and reputation impact of the disruption and ensure the long-term survival of the organisation.
Conclusion
Cybersecurity, business continuity and disaster recovery are three critical aspects of any organisation's operations. Cyber threats and incidents can have severe consequences for the organisation's reputation, finances, and overall business continuity. Therefore, it is essential to have a comprehensive incident response plan in place to mitigate the impact of such incidents and minimise the downtime. Similarly, business continuity planning helps organisations to ensure that their critical business functions can continue during and after a disruptive event and disaster recovery ensure that operations return to normal and learnings are made from every incident.A successful incident response, business continuity and disaster recovery strategy require proper planning, risk assessment, and recovery strategies. Organisations must identify their critical assets and processes, prioritise their recovery, and establish recovery time objectives (RTO) and recovery point objectives (RPO). Testing, training, and maintenance are also crucial to ensure that the plans are up-to-date and effective.
Ultimately, incident response, business continuity and disaster recovery planning should be part of an organisation's overall risk management strategy. By implementing these plans, organisations can minimise the risk of financial and reputation damage from a cyber incident or other disruptive event and ensure the continuity of their critical business functions.
Check your readiness with a Quiz: https://forms.office.com/r/myq2sMJqbi
Disclamer: This article is not legal or regulatory advice. You should seek independent advice on your legal and regulatory obligations. The views and opinions expressed in this article are solely those of the author. These views and opinions do not necessarily represent those of HSBC or its staff. Artificial Intelligence Technology was used to read-proof this article.